Natural Language Queries
CSE 662 Fall 2019
November 19
Data Access
Databases
Precise question → Precise answer
Search Engines
Vague question → Imprecise answer
Natural Language Queries
Vague question → Precise answer
Natural Langauge Queries
User: Return the average number of publications by Bob in each year.
Database: 5
- Not introspectable: How was 5 computed?
Natural Langauge Queries
User: Return authors who have more papers than Bob in VLDB after 2000.
- Synonyms: The table may be named "publications."
- Parenthesization: What clause do "in VLDB" and "after 2000" apply to?
- Ambiguity: VLDB could refer to the VLDB conference or the VLDB journal?
Natural Language Queries
- Parse: Derive the semantic structure of the sentence
- Mapping: Map the nodes of the sentence parse tree onto concepts.
- Structure: Shoehorn the nodes into a query-friendly structure.
- Iterate: Confirm interpretation with the user and repeat from 2 as needed.
- SQL: Generate and evaluate the query.
Parse
Recover sentence structure as a tree of concepts

(Implemented via the Stanford parser)
Mapping
Tag each node with a label describing its (lightly disambiguated) role in the query.
- Select Node (SN)
- The root of a projection
- Operator Node (ON)
- Any filtering predicate
- Function Node (FN)
- Any aggregation function
- Name Node (NN)
- A proper noun (with the relation or attribute it corresponds to)
- Value Node (VN)
- A numerical value (with the attribute it belongs to)
- Quantifier Node (QN)
- Generalization of a predicate to a collection (ANY/ALL/EACH)
- Logic Node (LN)
- Boolean predicate modifiers (AND/OR/NOT)
| Node | Tag | Metadata |
|---|---|---|
| return | SN | SELECT |
| author | NN | author |
| more | ON | > |
| paper | NN | publication |
| Bob | VN | author.name |
| VLDB | VN | conference.name |
| after | ON | > |
| 2000 | VN | publication.year |
Simple (Brute Force) Labeling
Select, Operator, Function, Quantifier, and Logic Nodes are schema-independent.
Pre-generate (semi-manually) a knowledge base of terms that correspond to each node type.
Schema-specific Labeling
Create a knowledge-base of every table name, attribute name, and cell value in the database.
(Ideally the user types in a noun phrase that is one of these)
Potential Problems
- Typos
- String similarity (e.g., Robort vs Robert).
- Synonyms
- Word2vec (wordnet) distance.
Given a parse tree node ($node$) and every schema element ($elem$), find the best match.
$$Sim(node, elem) = \textbf{max}(Jaccard(node, value), Word2vec(node, value))$$
- All $elem$ s.t. $Sim(node, elem) > \tau$
- Candidate nodes (potential matches)
- $\textbf{argmax}_{elem}(Sim(node, elem))$
- The best node
Every node that matches at least one schema element is labeled either NN or VN.
Every node that matches more than one schema element is ambiguous.
Leverage relationships exposed in the schema:
- Attributes and their relations
- Foreign-key-relationships
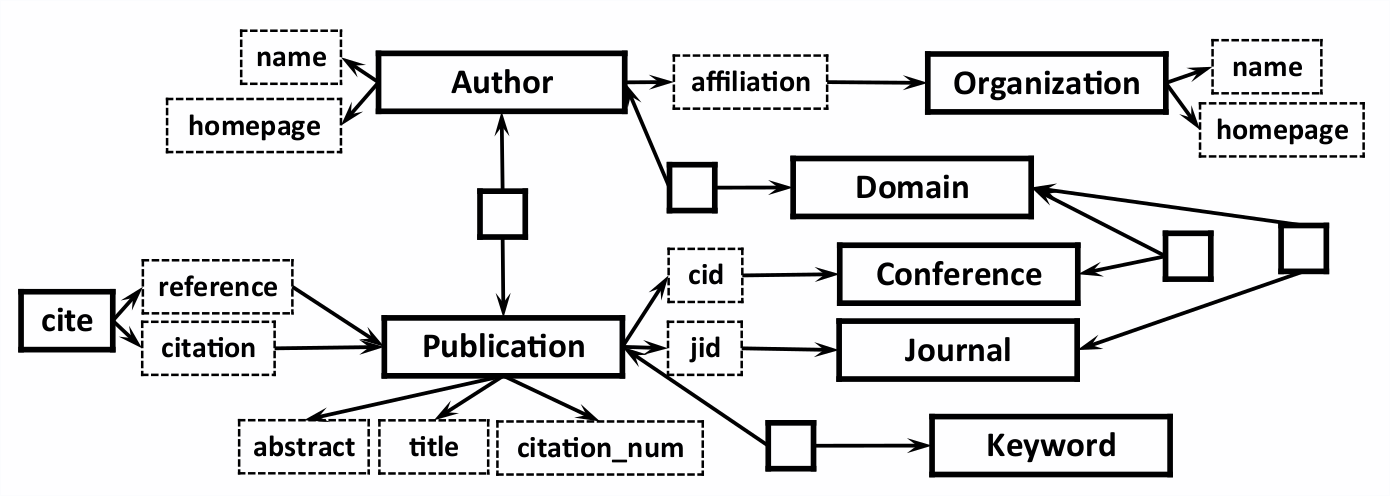
If proper noun A is an ancestor of proper noun B in the parse tree...
... attempt to minimize the distance between the tag of A and B in the schema graph.
Refining the Parse Tree
- The natural language parser may incorrectly relate words (need to fix errors).
- Human languages are redundant (need to "desugar" the parse tree).
- Elliptical statements are portions of a sentence that reference remote parts (need to replicate sentence parts).
Approach: Explore "similar" parse trees in the vicinity of the original parse tree.
Exploration Criteria
- Restrict language to a sub-grammar of permitted parse trees.
- Similar nodes should be close to one another.
- Don't explore too far.
Similarity of Close Nodes
Two NN or VN nodes are "close" in the parse tree if:
- One node is an ancestor of the other in the parse tree.
- No other NN or VN node lies between them in the tree.
We want close nodes in the parse tree to be close in the schema graph as well.
Exploration Algorithm
- Start with the original tree.
- Enumerate all 1 tree-edit distance edits.
- Save any edits that are permitted.
- Recur into each edit that doesn't make close nodes less similar.
Dynamic programming to avoid processing the same tree more than once.
Return all permitted edits encountered.
Implicit Nodes
ON (comparators) should have two descendents.
We expect:
- type(LHS) = type(RHS)
- rootNN(LHS) = rootNN(RHS)
Otherwise we copy the LHS subtree into the RHS.
